Noise does not necessarily decrease by averaging samples, particularly for a small number of samples. Both the Central Limit Theorem and the binomial distribution approximation to normal lose validity as N → 0.
Central Limit Theorem
When discussing small sample sets, assuming a Poisson distribution is often more appropriate than the Gaussian. The Central Limit Theorem is often used as a justification for assuming all noise is treated as Gaussian, but the CLT is based on the assumption of a “large” number of samples – “large” being a somewhat ambiguous term.
“The central limit theorem asserts that means of independent, identically distributed variables will converge to a normal distribution provided they are light-tailed enough. This means that even when the exact distribution is not known for some quantity, if there is some form of averaging process going on you will eventually end up with normal distributions. This is the basis for a long list of statistical decision procedures.“
More formally1:
Let  ,
,  , …
, …  be a set of N independent random variates and each
be a set of N independent random variates and each  have an arbitrary probability distribution
have an arbitrary probability distribution  with mean
with mean  and finite variance
and finite variance  . Then the normal form variate is:
. Then the normal form variate is:

and has a limiting cumulative distribution function which approaches a normal distribution.
Under additional conditions on the distribution of the addend, the probability density itself is also normal with mean  = 0 and variance
= 0 and variance  = 1. If conversion to normal form is not performed, then the variate:
= 1. If conversion to normal form is not performed, then the variate:

is normally distributed with  and
and 
Although this definition requires “identically distributed” samples, another version presented by Liapounov2 does not require identical distributions but does require finite mean and variance.
![\[ \, \lim\limits_{N \rightarrow \infty} \, \frac{1}{\, s_n^{2+\delta} \, } \, \sum\limits_{i=1}^n \mathbb{E} \left[ \left|\text{X}_i \, - \, \mu_i \right|^{2+\delta} \, \right] \; = \; 0 \]](https://davemcglone.com/wp-content/ql-cache/quicklatex.com-fde82f4b90737cc311e9d245c470919c_l3.png "Rendered by QuickLaTeX.com")
All well and good. Pay attention to the many conditions: “identically-distributed”, “light tailed enough”, “eventually end up with”, “N → ∞”, and most particularly, references to “large enough”. The CLT is an approximation based on large numbers. Electronic noise does not always follow these conditions and a “large number” is not defined.
My concern is the use of averaging. There exists a tendency to use the mathematics of a Gaussian distribution in situations it does not apply – so I need to determine what a suitable “large enough” number is.
Probability Distributions
Uniform Distribution:
All occurrences are constrained to well-defined limits. Any value within those limits has equal probability of occurrence. Tossing a single honest die is a good example: One of six possible outcomes, each outcome having equal probability
Binomial Distribution
Calculates the number of occurrences out of a fixed number of possibilities. Any single occurrence has probability p. The binomial distribution is approximated by a Gaussian distribution as the number of samples increases. The toss of a coin is a common example where it is assumed there are only two possible outcomes (though last time I looked at a coin, it had three surfaces). Probability of state in digital representation of white noise would be another example.
Gaussian Distribution
aka “normal” distribution. The “bell curve”. Commonly used to determine measurement errors. The normal distribution is a Gaussian distribution with mean of zero and variance of 1. A continuous approximation to the discrete binomial distribution for a very large number of samples. The Central Limit Theorem states that the mean of a large set of a variety of individual distributions tends towards a normal distribution … as the number of samples tends towards “very large”. Feller3 suggests a reasonable approximation requires a minimum of 5 samples.
Poisson Distribution
Calculates the number of occurrences within a given interval given the average number of occurrences per interval. Shot noise – photon and electron – has a Poisson distribution. The variance equals the mean. Tends to a binomial distribution as the number of samples increases.
I’ll be mostly concerned with the Gaussian and Poisson distributions – the point being that sample numbers are often not sufficient to make precise measurements based solely on Gaussian-based analyses. Low-frequency and low-level signals come to mind ..
Gaussian Addition and Multiplication
If one Gaussian measure of x + σ is added to another x
+ σ is added to another x + σ, the sum of these two Gaussian distributions would have a Gaussian mean of x + x but the distribution of uncertainty would be:
+ σ, the sum of these two Gaussian distributions would have a Gaussian mean of x + x but the distribution of uncertainty would be:

If the measures were multiplied, the product would have mean x times x but the distribution would be:
times x but the distribution would be:

Skewness and Kurtosis
Skewness is a measure of symmetry while kurtosis is a measure of concentration of data about the mean (fatness of curve). Positive skewness implies data with a longer right-sided tail; negative skewness implies data toward a a longer left-sided tail. Kurtosis greater than 3 implies a “peakiness”; less than 3 indicates “flatness”.
The Gaussian distribution has kurtosis of 3.0 and skewness of 0. For the number of samples N to be “large enough”, the kurtosis and skewness of the resulting Poisson function must approach these values.
The Poisson distribution has kurtosis of 3 +  with skewness of
with skewness of  . For 10 samples, kurtosis is 3.1; skewness is 0.316. For 5 samples, kurtosis is 3.2; skewness is 0.447. The Gaussian values are kurtosis of 3.0 and skewness of 0. Data sets of 5 and 10 samples do not fit the criteria of “large enough”.
. For 10 samples, kurtosis is 3.1; skewness is 0.316. For 5 samples, kurtosis is 3.2; skewness is 0.447. The Gaussian values are kurtosis of 3.0 and skewness of 0. Data sets of 5 and 10 samples do not fit the criteria of “large enough”.
A Mathematica routine to explore “large” is used:
data[n_] := TransformDistribution[Total[Array[x,n],
Array[x,n]  ProductDistribution[{PoissonDistribution[1],n}]]
ProductDistribution[{PoissonDistribution[1],n}]]
Table[Skewness[data[n]],{n, 1, 10 001, 1000}]//N
Table[Kurtosis[data[n]],{n, 1, 10 001, 1000}]//N
This routine provides the values for skewness and kurtosis for 1 to 10001 samples by 1000. The results follow:

I’d be willing to state that even 1001 samples is a close representation of a normal distribution. Perhaps if I were measuring resistance values in a lab, I could effectively collect even more than 1000 samples … high speed clock and all. But I also suspect I could get by with fewer samples.
So repeat with increments of 100 up to 1000.

“Hundreds” gets into the range of “how good does it need to be?”. The shape of the “bell” is good throughout the range but there’s a tendency to emphasize the higher values.
Try again by 10s to 100.

A little bit extra emphasis towards the mean and skewed a bit high. I need 34 samples before kurtosis gets within 1% of the Gaussian ideal value of 3. Poisson skewness is 0.171 at N = 34. This would tend to over-estimate the mean if Gaussian assumptions are used.
When taking field measurements, it may not be possible to collect more than a couple of samples … and it may not be desirable to do so, but since the tendency is to average everything under the assumption of a Gaussian distribution, let’s see how close a smaller number of samples gets.

By making the assumption that mean and variance are known, the use of only a few samples is validated … assuming the assumption is true. Since determining a “mean” is often the point of the measurement, the assumption is not valid.
Although an argument might be made that 10 samples suitably represents a “bell” shape, the skewness (which should be close to zero) is large enough that the assumption of Gaussian characteristics for improvement by averaging is not valid. Furthermore, it is quite likely that field measurements – especially with moving platforms – do not meet the stationary criteria. It would also appear that the Central Limit Theorem allowing samples of disparate distributions to be combined as Gaussian “in the limit” is not valid for such small numbers of samples.
On the other hand, how “valid” do you wish to be? (Possibly more so than this.)
What is the desired accuracy of the results?
Think of it this way. The Poisson distribution is based on positive integers. While there is room to “spread” the tail towards more positive values, there is less room to spread to the less positive values as the number of samples decreases – the distribution gets “squished” at 1 as the number of samples decreases.
Perhaps a few plots would be clearer than a list of numbers:
The Poisson Distribution for 1, 2, 5, and 10 samples. By eye, 10 samples looks close to a Gaussian; the skewness of 0.316 shows it tends fairly strongly to the right with a slight tendency to over-emphasize values to the mean.
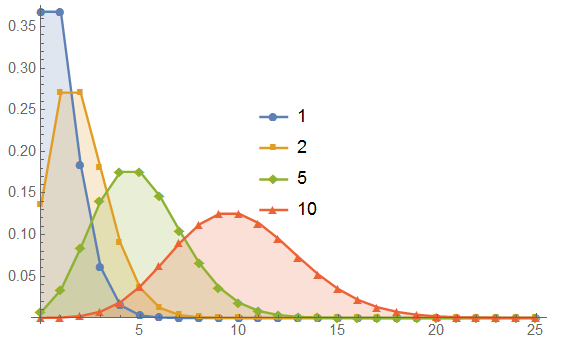
If I were making measurements such as this and using the assumption of Gaussian distribution, I might be inclined to report a mean value a bit higher than the “true” value.
Looking at a comparison to the Gaussian (in RED) shows a not-bad closeness to the bell shape, but the left tail is cut off.
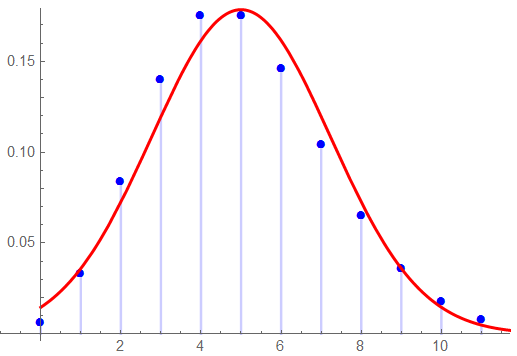
The Gaussian representation is in RED, the measured data is in BLU. Note the truncation at 1 – hard to have fewer than 1 sample …
The skewness of the Gaussian representation is 0.996; the kurtosis is 4.1. Analyzing this data set with Gaussian assumptions is not valid.
Of course, one should note that this distribution has 10 samples – of a stationary system. This may not be feasible with field measurements. The point being that the process of averaging to improve the measurement quality is based on assuming the validity of the Central Limit Theorem, Gaussian probabilities, and a stochastic sample set. These assumptions do not appear to be valid for small numbers of samples … and it may not be feasible to collect a sufficient number to be considered “large”.
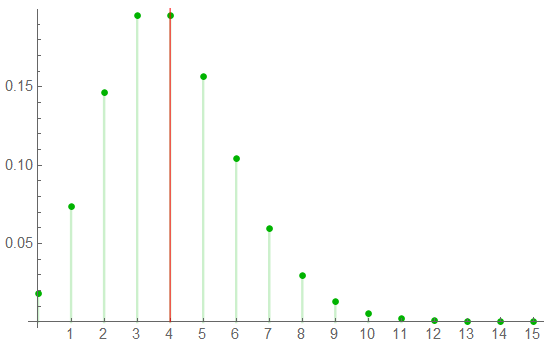
A sample set of 4 is not uncommon. Under Gaussian analysis, averaging 4 samples will reduce the variance by ½. The Poisson distribution mean is the number of “occurrences”. The statistical characteristics are defined by the mean : the variance is equal to the mean, the skewness is 1/ , and kurtosis is 3 + 1/.
, and kurtosis is 3 + 1/.
The first of the following charts shows the Poisson variance for 4 samples;
The second shows a possible shift in measure over 10 sets of 4 samples.
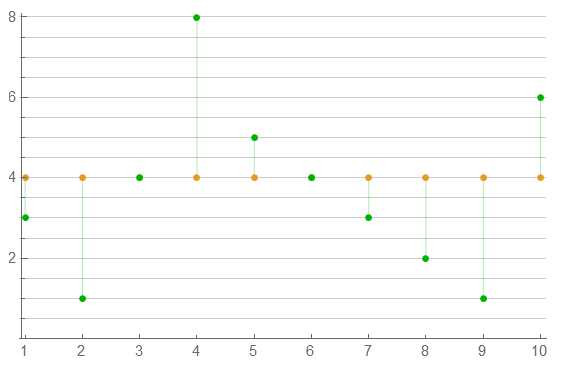
That’s good for now.
![]()
1Weisstein, Eric W. “Central Limit Theorem.” MathWorld–A Wolfram Web Resource
2Thomas, John B. “An Introduction to Applied Probability and Random Processes
3Feller, W. “An Introduction to Probability Theory and Its Applications